Overview:
The Decision Tree Classifier is a versatile and powerful tool in machine learning. OtasML provides a user-friendly interface for configuring and optimizing decision trees, allowing users to tailor the algorithm to their specific needs. Below is a detailed guide to the configurable parameters for the Decision Tree Classifier in OtasML.
Configurations page:
The Configurations page allows users to adjust various parameters of the Decision Tree Classifier. Here are the details:
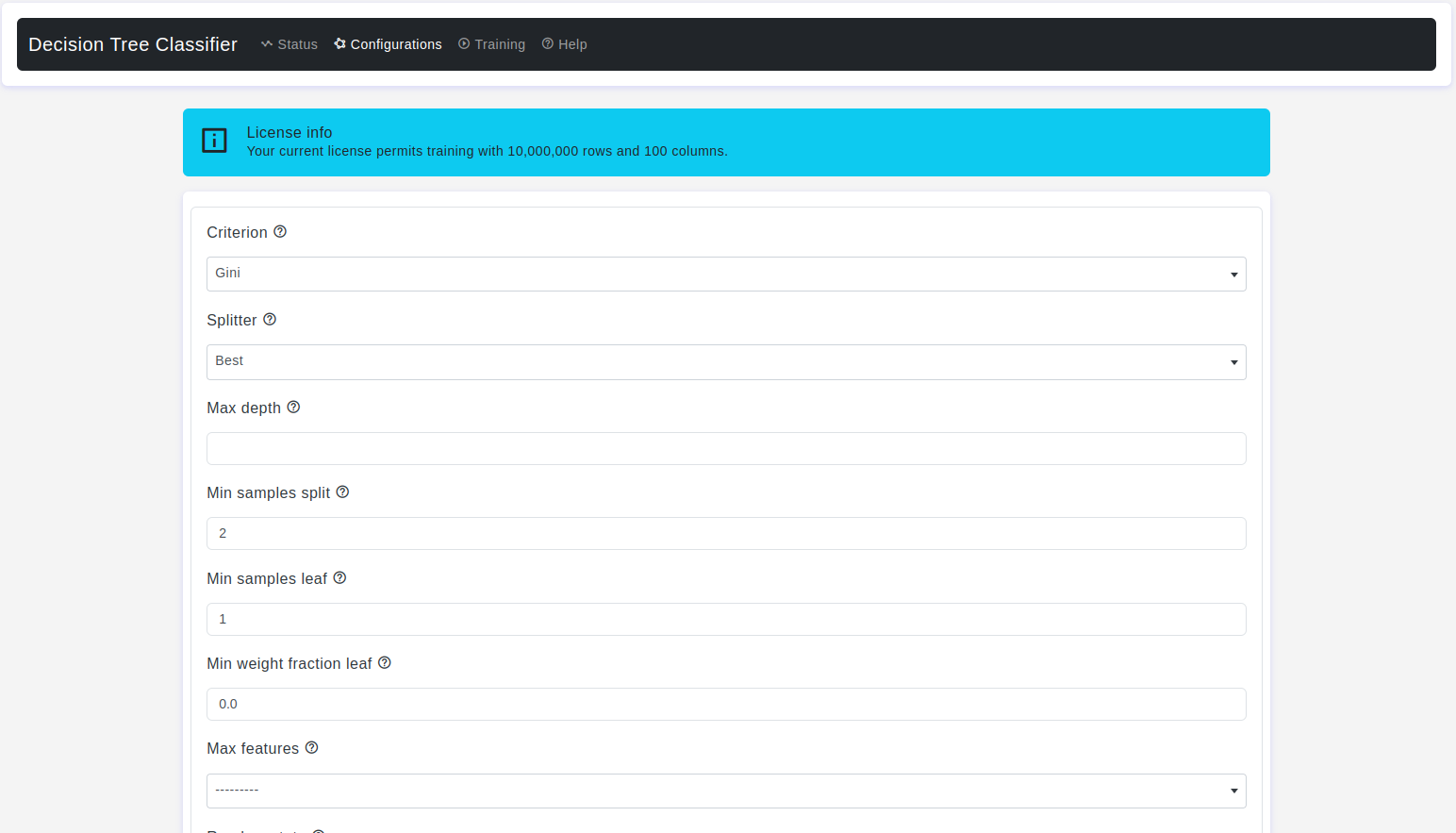
Criterion
- Default Value: Gini
- Description: It is a parameter used to specify the measure of impurity or quality used for making decisions about how to split the data at each node of the decision tree.
Gini:This criterion uses the Gini impurity, which measures the level of impurity or disorder in a set of samples. It quantifies how often a randomly selected element from the set would be incorrectly classified. A lower Gini impurity indicates a more pure node with samples belonging to the same class.Entropy:This criterion uses the entropy of the class distribution in a node. Entropy measures the uncertainty or randomness in a set of samples. A lower entropy indicates a more pure node with samples belonging to the same class.Log loss:This allows you to use log loss as a criterion for splitting nodes in the decision tree, in addition to the previously mentionedginiandentropycriteria.
Splitter
- Default Value: Best
- Description: It allows you to choose the strategy used for selecting the feature and value that determine how to split the data at each node of the decision tree.
best:This is the default value. The algorithm evaluates all possible splits and chooses the one that results in the highest quality of the split, as determined by the chosen criterion (e.g.,gini,entropy, orlog_loss).random:This strategy randomly selects a subset of features at each node and then evaluates the best possible split from this subset. It can introduce randomness to the decision tree's construction and is often used to prevent overfitting.
Max Depth
- Default Value: None
- Description: This parameter controls how deep the decision tree can grow by limiting the number of levels in the tree. A deeper tree can capture more complex patterns in the training data, but it can also lead to overfitting, where the model memorizes the training data and performs poorly on new, unseen data.
Min Samples Split
- Default Value: 2
- Description: This parameter is used to set the minimum number of samples required to split an internal node during the construction of the decision tree. The
min samples splitparameter is used to control the complexity of the decision tree and can help prevent the tree from creating splits that result in very small subsets of the data. Setting a higher value formin samples splitcan help reduce overfitting by ensuring that each internal node has a minimum number of samples before attempting to split further.
Min Samples Leaf
- Default Value: 1
- Description: This parameter is used to specify the minimum number of samples that must be present in a leaf node during the construction of the decision tree. The
min samples leafparameter controls the stopping criterion for growing the tree. If a split would result in a leaf node with fewer samples than the specifiedmin samples leaf, the split is not made, and the node becomes a leaf node. This parameter helps prevent overfitting by requiring each leaf node to have a minimum number of samples. - Warning: Using a higher value for
min samples leafcan lead to simpler and less complex decision trees, as it prevents the algorithm from creating very small leaf nodes that might capture noise or outliers in the training data.
Min Weight Fraction Leaf
- Default Value: 0.0
- Description: This parameter controls the minimum weighted fraction of the sum total of weights of input samples that are required to be at a leaf node. This parameter becomes relevant when you have samples with varying weights, which might occur when using weighted data for training.
Max Features
- Default Value: None
- Description: This parameter is used to control the number of features that the algorithm considers when looking for the best split at each node of the decision tree.
None: In this case, all features are considered for every split, allowing the algorithm to evaluate all possible splits.Auto: This means the algorithm will consider the square root of the total number of features at each split. For example, if you have 100 features, it will consider around 10 features at each split.Sqrt: Same asauto, it considers the square root of the total number of features.Log2: The algorithm considers the logarithm base 2 of the total number of features at each split.
Random State
- Default Value: None
- Description: It is a parameter that allows you to control the random number generator used for various random processes during the training and evaluation of the model. These random processes can include initializing the model's coefficients, shuffling the dataset, or splitting the data into training and testing subsets.
- Warning: The features are always randomly permuted at each split, even if the splitter is set to
best.
Max Leaf Nodes
- Default Value: None
- Description: It is used to set the maximum number of leaf nodes that the decision tree can have during its construction. The
max leaf nodesparameter is used to control the complexity and size of the decision tree by specifying the upper limit on the number of leaf nodes. When this parameter is set, the algorithm will stop growing the tree if the number of leaf nodes reaches or exceeds the specified value.
Min Impurity Decrease
- Default Value: 0.0
- Description: It is used to set the minimum impurity decrease required to perform a split at a node during the construction of the decision tree. The impurity decrease is calculated based on the chosen impurity criterion (e.g.,
gini,entropy, orlog_loss) and represents the improvement in impurity that a potential split would bring to the tree. A split is only considered if the impurity decrease resulting from the split is greater than or equal to the specifiedmin impurity decrease. - Warning: Setting a higher value for
min impurity decreasecan lead to fewer splits and a more conservative growth of the tree. It can help prevent overfitting by only allowing splits that provide a significant reduction in impurity.
Class Weight
- Default Value: None
- Description: This allows you to assign different weights to different classes in the target variable. The
class weightparameter is used to handle imbalanced class distributions, where certain classes have fewer samples compared to others. Imbalanced classes can lead to biased models, as the algorithm might prioritize the majority class at the expense of minority classes. By assigning different weights to classes, you can influence the decision tree's learning process to give more importance to underrepresented classes.NoneAll classes are treated equally, and no special weighting is applied.balancedThis option automatically adjusts the weights inversely proportional to the class frequencies in the input data. It helps mitigate the impact of class imbalance.
Ccp Alpha
- Default Value: 0.0
- Description: Means stands for
Cost-Complexity Pruning alpha.It is a parameter used for pruning decision trees based on the concept of minimal cost-complexity. Pruning is a technique used to prevent overfitting in decision trees by removing branches that do not contribute much to improving the overall model's performance on unseen data. The goal of pruning is to find a simpler tree that generalizes better to new data. - Warning: The
ccp alphaparameter controls the trade-off between tree complexity and accuracy. A smaller value ofccp alphaencourages the algorithm to produce a more complex tree with potentially better accuracy on the training data. However, this could lead to overfitting. On the other hand, a larger value ofccp alphaencourages the algorithm to prune the tree more aggressively, resulting in a simpler and more generalizable model.
Test Size
- Default Value: 0.2
- Description: The
test sizeparameter is used when splitting the dataset into these subsets, and it specifies the portion of the data that will be used for testing.
Train Size
- Default Value: 0.8
- Description: The
train sizeparameter is used when splitting the dataset into these subsets, and it specifies the portion of the data that will be used for model training.
Conclusion
OtasML’s configuration options for the Decision Tree Classifier empower users to build robust, tailored models by adjusting key parameters. Whether you need to control the tree's depth, manage sample splitting criteria, or handle class imbalance, OtasML provides the flexibility needed to optimize performance for diverse datasets. Explore these settings to fine-tune your Decision Tree Classifier and achieve superior predictive accuracy with OtasML.