Introduction
Feature scaling is a crucial preprocessing step in machine learning that ensures all features in a dataset are on a comparable scale. This standardization or normalization process can significantly enhance model training and performance by mitigating the impact of features with varying magnitudes. OtasML, a visual machine learning tool, offers a comprehensive Feature Scaling option within its data preparation model. This article explores the various feature scaling methods available and how they can be configured to optimize your machine learning workflows.
Configurations Page
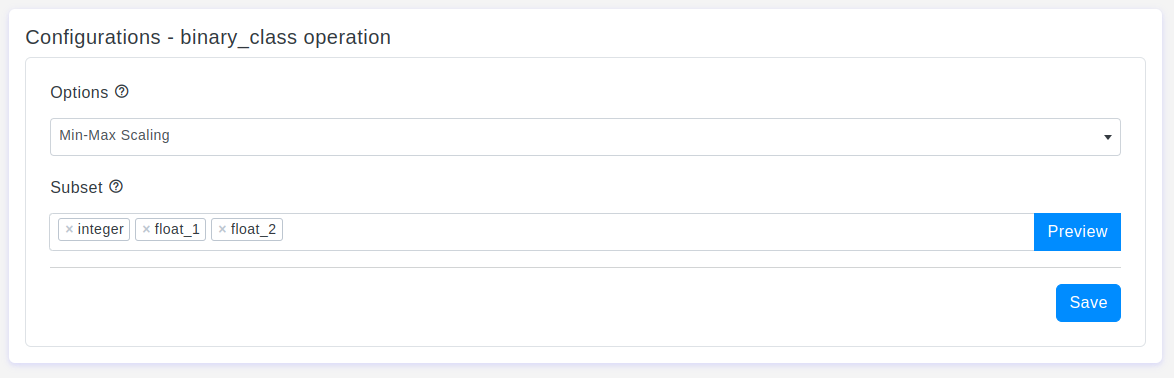
The Feature Scaling tool in OtasML provides a range of scaling techniques, allowing users to tailor the preprocessing step to their specific needs. Below are the key configurations and options available:
Options
-
Default Value: Min-Max Scaling
-
Description: Feature scaling is used to standardize or normalize the range of independent variables in a dataset. This ensures that features are on a similar scale, facilitating better model training and improved performance. The available scaling options include:
Min-Max Scaling:Scales features to a fixed range, usually between 0 and 1. This is the default setting and is useful for preserving relationships between features while maintaining their relative importance.Standardization:Scales features to have a mean of 0 and a standard deviation of 1. This method is effective for algorithms that assume normally distributed data.Robust Scaler:Scales features using statistics that are robust to outliers, such as the median and interquartile range.MaxAbsScaler:Scales features by dividing by the maximum absolute value. This method is useful for data that is already centered at zero but not scaled.PowerTransformer:Applies a power transformation to make data more Gaussian-like. This can help stabilize variance and minimize skewness.QuantileTransformer:Transforms features to follow a uniform or normal distribution, which can be useful for non-linear transformations.Normalizer:Scales each sample to have unit norm (e.g., L1 or L2 normalization), which is useful for sparse datasets and models that rely on the angle between vectors.
Subset
- Default Value: None
- Description: The Subset option allows users to select specific columns for feature scaling. This ensures that only the desired features are scaled, providing more control over the preprocessing step and allowing users to exclude columns that do not require scaling.
Interactive Buttons: Preview and Save
To enhance user experience and provide greater control over the feature scaling process, the tool includes two essential buttons:
Preview:This button allows users to see the effects of the selected feature scaling method in real-time without permanently applying the changes. By clicking Preview, users can visually assess how the dataset will be altered based on the current configurations, ensuring that the scaling method is appropriate before committing to any changes.Save:Once users are satisfied with their configurations and the preview results, they can click the Save button to permanently apply their chosen settings. This action saves the configuration, which will then be applied to the data during the training process, ensuring that the feature scaling aligns with the user's expectations and requirements.
Conclusion
The Feature Scaling tool in OtasML provides a robust solution for normalizing and standardizing features in a dataset, a crucial step in the machine learning pipeline. By offering a variety of scaling methods and the ability to selectively apply them to specific columns, users can effectively tailor the preprocessing step to their specific needs. The inclusion of interactive Preview and Save buttons further enhances control and confidence in the scaling process. OtasML continues to empower users with intuitive and powerful tools, making data preparation a seamless and integral part of the machine learning workflow.