Overview:
In the fast-evolving field of machine learning, the capability to create, train, and evaluate models efficiently is crucial for both novice and seasoned data scientists. OtasML stands out as a visual machine-learning tool designed to simplify these processes, enabling users to interact intuitively with complex algorithms. This article delves into the specifics of Naive Bayes, particularly the CategoricalNB classifier, within OtasML, and explains how various configurations can be adjusted for optimal model performance.
Configurations page:
The Configurations page is where users can fine-tune the settings of the CategoricalNB classifier. Let’s explore these parameters in detail:
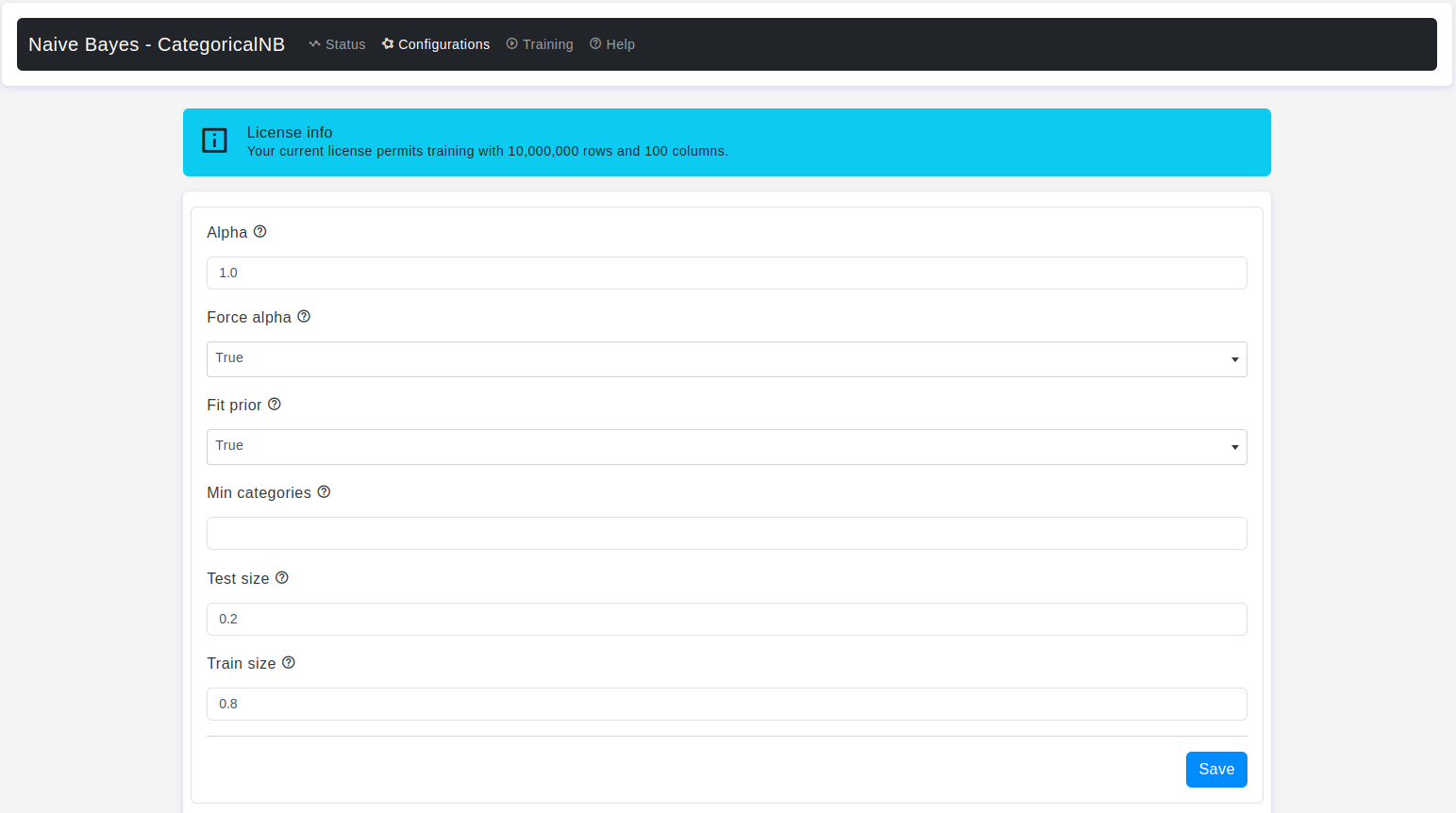
Alpha
- Default Value: 1.0
- Description: It is a smoothing parameter used in the calculation of probabilities, and it is used to add smoothing to the probabilities calculated during the training phase. Smoothing is often employed to prevent zero probabilities and mitigate the impact of missing features in the training data, which could lead to unreliable probability estimates.
- Warning: Set
alpha=0andforce alpha=True, for no smoothing
Force Alpha
- Default Value: True
- Description: If
Falseandalphais less than 1e-10, it will setalphato 1e-10. If True,alphawill remain unchanged. This may cause numerical errors ifalphais too close to 0.
Fit Prior
- Default Value: True
- It is used to control whether or not class priors should be learned from the training data. Class priors are the probabilities of each class occurring in the dataset, and they play a role in the Naive Bayes algorithm's probability calculations.
True:If set to True, the class priors will be learned from the training data. This means that the prior probabilities of classes will be estimated based on the relative frequencies of each class in the training data.False:If set to False, the class priors will not be learned from the training data. Instead, equal prior probabilities will be assumed for all classes.
Min Categories
- Default Value: None
- Description: Specifies the minimum number of categories required for each feature during training. This helps manage the impact of features with very few categories that might not provide reliable information for classification.
Test Size
- Default Value: 0.2
- Description: The
test sizeparameter is used when splitting the dataset into these subsets, and it specifies the portion of the data that will be used for testing.
Train Size
- Default Value: 0.8
- Description: The
train sizeparameter is used when splitting the dataset into these subsets, and it specifies the portion of the data that will be used for model training.
Conclusion
OtasML provides a user-friendly interface for configuring the CategoricalNB classifier. By understanding and utilizing the detailed configurations available, users can fine-tune their models to achieve the best performance on their datasets. Whether adjusting the alpha parameter for smoothing, setting the appropriate train-test split, or managing feature categories, OtasML empowers users to build accurate and reliable models with ease. Explore OtasML today and elevate your data science projects with visual machine learning.