Overview:
Support Vector Machines (SVM) for regression, known as Support Vector Regression (SVR), is a robust and flexible machine learning algorithm used for various regression tasks. OtasML provides extensive configuration options for fine-tuning SVR models to achieve optimal performance.
Configurations page:
The Configurations page allows users to adjust various parameters of the SVR model. Here are the detailed configuration options:
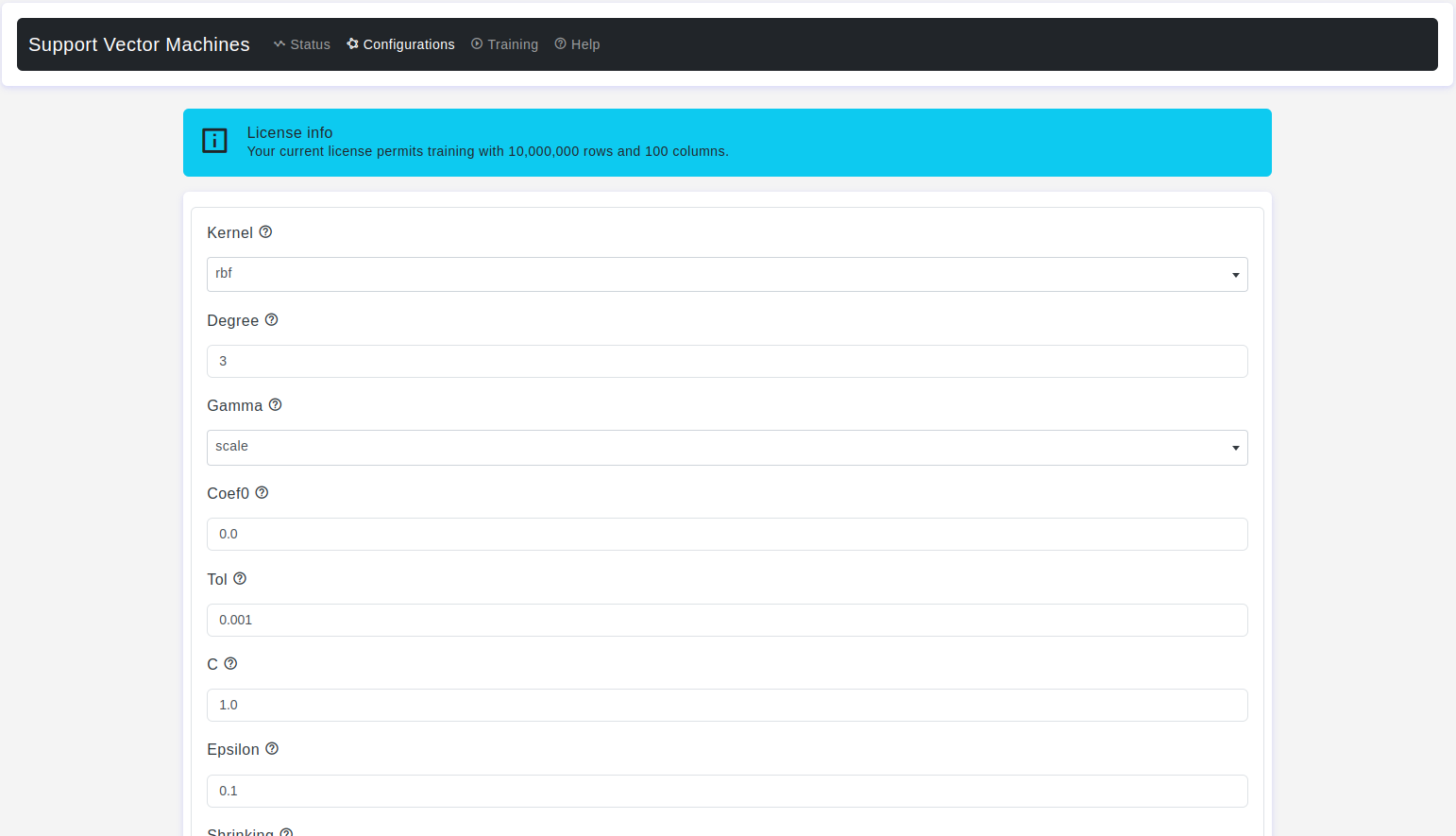
Kernel
- Default Value: rbf
- Description: It is used to specify the kernel function that is used to map the input features into a higher-dimensional space. The choice of kernel function has a significant impact on the performance of the support vector machine for regression tasks.
linear: This option specifies a linear kernel, which is suitable for linear regression-like problems. It applies a linear transformation to map the input features into a higher-dimensional space.poly: This option specifies a polynomial kernel, which can capture polynomial relationships between the input features and the target variable. You can specify the degree of the polynomial using the degree parameter.rbf(Radial Basis Function): The RBF kernel is also known as the Gaussian kernel. It is a common choice and is capable of capturing non-linear relationships in the data. It maps the input features into an infinite-dimensional space.sigmoid: The sigmoid kernel maps the input features using a sigmoid function. It is suitable for problems where the relationship between features and the target variable is similar to a logistic function.
Degree
- Default Value: 3
- Description: It is applicable when you choose the polynomial kernel
kernel=poly. The degree parameter specifies the degree of the polynomial used in the kernel function.
Gamma
- Default Value: scale
- Description: This parameter is a crucial hyperparameter that affects the shape and flexibility of the kernel function, particularly for the Radial Basis Function (RBF) kernel. The gamma parameter controls the smoothness or the wiggliness of the decision boundary or function learned by the SVR model.
scale: If you setgamma=scale, the gamma value is automatically calculated based on the scale of the input features. It is computed as 1 / (n_features * X.var()), where n_features is the number of features in your data, and X.var() is the variance of the data along each feature.auto: If you setgamma=auto, it is equivalent to using thescalecode> option. The gamma value is computed in the same way based on the feature scale.
- Warning: Kernel coefficient for
rbf,polyandsigmoid.
Coef0
- Default Value: 0.0
- Description: The coef0 parameter, also known as the bias term, is used to control the influence of the constant (bias) in the kernel function. The coef0 parameter determines how much the model relies on the constant term when making predictions.
- Warning: It is only significant in
polyandsigmoid.
Tol
- Default Value: 1e-3
- Description: The tol parameter, short for tolerance, specifies the tolerance for stopping criteria during the training process. It controls when the training process should stop if certain conditions are met.
C
- Default Value: 1.0
- Description: It is a hyperparameter that controls the regularization strength of the SVR model. It determines the trade-off between maximizing the margin (distance between the support vectors and the decision boundary) and minimizing the training error.
- Warning: Must be strictly positive. The penalty is a squared l2 penalty.
Epsilon
- Default Value: 0.1
- Description: The epsilon parameter, often denoted as ε (epsilon), is a hyperparameter that controls the margin of tolerance in the SVR model. It specifies the size of the epsilon-insensitive tube around the regression line or hyperplane. This parameter is used to control the trade-off between fitting the training data closely and allowing some margin for errors.
- Warning: Must be non-negative.
Shrinking
- Default Value: True
- Description: It refers to a technique used to accelerate the training process and reduce the computational complexity of solving the SVM optimization problem. This technique is known as
shrinkingbecause it reduces the number of support vectors considered during the optimization process.
Cache Size
- Default Value: 200
- Description: It specifies the size of the kernel cache used during training. The kernel cache is a memory buffer that stores intermediate results of kernel computations to speed up the training process.
- Warning: In MB
Verbose
- Default Value: False
- Description: It is a parameter that controls the level of verbosity or the amount of information that the SVR model outputs during the training process. It can be helpful for monitoring the progress of training or for debugging purposes.
Max Iter
- Default Value: -1
- Description: It is a parameter that determines the maximum number of iterations for the optimization solver to converge during the training process. The optimization solver is responsible for finding the optimal hyperplane that minimizes the loss function while respecting the margin constraints.
- Warning:
-1for no limit.
Test Size
- Default Value: 0.2
- Description: The
test sizeparameter is used when splitting the dataset into these subsets, and it specifies the portion of the data that will be used for testing.
Train Size
- Default Value: 0.8
- Description: The
train sizeparameter is used when splitting the dataset into these subsets, and it specifies the portion of the data that will be used for model training.
Conclusion
OtasML’s configuration options for SVR models enable users to tailor their models to specific datasets and prediction tasks. Adjusting parameters such as kernel, degree, and gamma can significantly impact the model’s performance and flexibility. Use this guide to fine-tune your SVR models and achieve superior predictive accuracy with OtasML.